by Carly Rector
Carly Rector runs CO2ign Art and NeonMob, platforms for digital art collecting. She has a 15+ year background working with machine learning at Amazon, and is a long-time patron of digital art. She gives an overview of recent developments in generative AI and how they impact artists and the art industry.

Midjourney V4 output for “Afghan girl.” Midjourney no longer permits this prompt. (Source: Twitter/Midjourney Discord)
What is generative AI?
AI or “artificial intelligence” is a bit of a buzzword. Computers aren’t actually “intelligent.” AI, or more accurately “machine learning,” refers to a specific type of computer program.
Anything you do on a computer—add together numbers in a spreadsheet, invert colors in an image, play music—has traditionally required someone to write down the instructions very literally on how to do it via writing code. Machine learning is used for processes that are too complicated for a person to define the steps for, either because that would take a very long time, or because they don’t actually know the steps.
Instead, the person provides a huge number of examples of what they want to do, and by trial and error with some complex mathematics, the computer “learns” to accomplish it as well as it can. The process of doing this is called “training” and the mathematical process that the computer figures out is called the “model.”
There are several types of machine learning models. The most common are classifiers—a model that puts what is given into categories. One classifier we’ve all encountered is spam detection. By being given billions of emails that have been marked as either spam or not, a system can calculate what features tend to indicate spam, such as typos, certain words in the subject line, formatting, sender, and so on. It doesn’t need a human to identify them individually. This model can then be used to classify new emails as spam or not.
“Generative” models are a different type of model which generates content rather than just classifying it. With a generative model, you train it on millions of images labeled as cats, and then you can prompt for a cat, and the model will create one.

Image generated in Midjourney for prompt “kitten leaping and jumping in air, garden, Pixar style, 3D, depth of field” (Source: Midjourney community showcase)
Is generative AI a new breakthrough? Why is it suddenly a big deal?
Generative models have existed since at least the late 2000s. But there have been several high-profile models released publicly in the last couple of years. These include DALL-E, Stable Diffusion and Midjourney for images, and ChatGPT, Bing AI, and Google’s Bard for text. These models provided such dramatically better performance than previous ones that they very swiftly had wide use. ChatGPT set a record for reaching 100 million users only two months after launch. Midjourney hosts the largest Discord server in the world, with 15 million members.
There are a few reasons why these models are so much better. The most basic one is that models do better when trained on more data. Training on huge amounts of data requires processing power that wasn’t generally available until recently. It’s also often difficult to actually gather the data itself.
These recently released models are so powerful, and controversial, because they’re trained on massive amounts of data taken from the internet without any explicit permission. Like a bot crawling a web page to index it for Google, anything that’s publicly available online can be accessed and saved for model training. ChatGPT pulled training data from millions of websites. Stable Diffusion was trained on LAION-5B, a dataset of five billion images with captions scraped from across the web.
What sorts of images are in these training datasets?
Almost everything you can think of. The website haveibeentrained.com lets you search to see if your work has been included by keyword or by image. Some of the top sources of images include Pinterest, Shopify, Ebay, Amazon, WordPress, Fine Art America, and Getty Images.
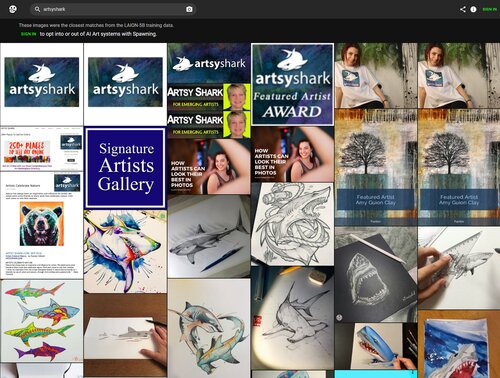
Caption: A search for “artsyshark” on haveibeentrained.com
What does an image being in the training data mean? Is this copyright infringement?
Any given image in the training dataset was only one of the examples used when the model “learned” how to create images. Notably, the original image is not directly retrieved when someone prompts the model. Whether this is copyright infringement is an open question. There are two warring perspectives on this:
Perspective #1 is that the computer is “learning” like a human learns, and humans are allowed to look at whatever they want online, so this is fair use under copyright. It isn’t infringing any more than a human referencing Google Images while they learn how to draw.
Perspective #2 is that “machine learning” isn’t human learning. What it’s doing is closer to compressing all the images into a very small format and retrieving them later. It isn’t copying them with 100% accuracy, but still essentially copying.
Generative models can in fact output images that very closely match examples from their training data. In machine learning terminology, this is called “overfitting.” Overfitting means learning to replicate specific pieces of the training data rather than generalizing the process.

Stable Diffusion output replicating a Getty Images watermark. Source: The Verge/Stable Diffusion
Getty Images is suing Stable Diffusion for use of their images. A group of artists have filed a lawsuit against Stable Diffusion and Midjourney. These lawsuits are still in progress at this time.
How are these image models currently being used?
OpenAI (DALL-E), Midjourney, and Stability AI (Stable Diffusion) are companies which build models and then offer use of them to clients. DALL-E allows users to generate images for paid credits. Midjourney offers subscription plans. Stable Diffusion is an open-source model that many other generative tools are built on top of, in addition to offering its own tool, DreamStudio.
It’s extremely easy for anyone to sign up and generate images. Images generated by these tools are more and more frequently used for illustrations, stock images, concept art, and many other applications.
What effect does this trend have? What are art platforms doing about it?
Generative AI can create images near-instantaneously. A user can generate hundreds or thousands of images a day using Stable Diffusion or similar tools. Stock image services, portfolio sites, and many other creative platforms are seeing a huge increase in the amount of AI work being submitted, which can overwhelm work from artists creating by hand.
Given the flood of content as well as the current controversies around copyright, several platforms have recently taken a stand on whether work creating using generative AI is allowed. Other platforms have been criticized heavily for not doing so in the face of the negative effects it has on artists. Some notable policies:
Platforms with restrictions on AI:
- Getty Images has banned AI images.
- ShutterStock has a partnership with OpenAI and only allows AI images generated through their tool, which is trained on licensed images from their catalog.
- NeonMob’s AI art policy does not allow AI images generated by models trained on images with third-party copyrights.
- Steam does not allow game submissions with art assets generated by models with third-party copyrights.
Platforms that allow AI submissions:
- Adobe Stock allows AI images as long as they are labeled as such, as long as “appropriate rights” for the images are acquired, including model releases for likenesses of real people/places. Adobe also has their own generator, Firefly, trained on Adobe Stock images. (Firefly is currently in beta and not available for commercial use.)
- DeviantArt allows AI images, but requires labeling them as such. They have their own Stable Diffusion-based generator, DreamUp. They also introduced an opt-out mechanism to indicate to web crawlers you don’t want your work used as training data.
- ArtStation allows AI images, a subject of a recent protest.
How can I protect my art?
There are a few things you can do currently.
Have I been trained? allows you to opt-out your art from the LAION dataset that Stable Diffusion uses. Note that this will only remove it from future versions of models once they’re re-trained on the dataset respecting the opt-out. Since the Stable Diffusion model is open source, users can continue to use older models.
The University of Chicago has released a tool called Glaze which adds human-imperceptible visual noise to an image that interferes with model training. If you have new work you’re concerned about posting online, this can help protect it from being replicated by ML models.
However, images that are already online are difficult to completely exclude from model training. This is particularly true if they’re hosted multiple places, or if someone unscrupulous is doing the training.
In the longer term, you can support groups like the Concept Art Association. They are working to advocate for more standards and legal protections that prevent training models on data without consent. Artist and CAA board member Karla Ortiz recently spoke to the Senate Judiciary committee on the topic. Decisions made on this now will have big implications for artists in the near future.

This amazing article has information that is completely new to me, a professional artist. Thank you for this info. Now I know where to begin to explore this important topic.
Someone has stolen ALL my pictures (Photos and Paintings) and I can’t get the file back. Any suggestions?